Maximizing Efficiency: A Guide to Optimizing Large Language Model (LLM) Inference with AWS Inferentia2
By Shane Garnetti
- 3 minutes read - 608 words
Understanding AWS Inferentia2
AWS Inferentia2 is a custom-built ML inference chip designed to deliver high performance at low cost. It supports all major ML frameworks, including TensorFlow, PyTorch, and MXNet, and offers flexible options for instances and type of processors (CPUs or GPUs). This flexibility makes it an excellent choice for running LLM inference tasks.
The Inf2 instance fundamentally integrates up to 12 Inferentia2 devices, with each Inferentia2 unit consisting of 2 NeuronCore-v2. Inferentia2 represents the second-generation, purpose-designed machine learning inference accelerator from AWS. A depiction of the Inferentia2 device’s architectural framework is provided below:
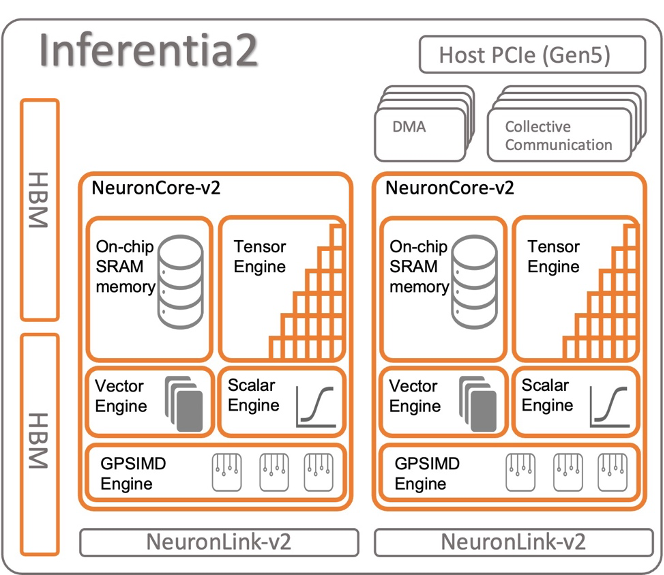
Reference Architecture: https://awsdocs-neuron.readthedocs-hosted.com/en/latest/general/arch/neuron-hardware/inferentia2.html
Optimizing LLMs with Inferentia2
The high throughput and low latency of AWS Inferentia2 allow it to run large machine learning models efficiently. Here are the steps to optimize your LLMs with Inferentia2:
To start, you’ll need to deploy your large language model on AWS. Use the AWS Management Console, AWS Command Line Interface (CLI), or AWS SDKs to launch an Amazon Elastic Inference instance with Inferentia2.
-
Choose the right instance type: Choosing the right instance type for your LLM is critical to optimizing performance. Inferentia2 is compatible with various instance types. Based on the size and requirements of your model, you can select the one that best fits your needs.
-
Use Neuron SDK: AWS Neuron is the SDK for Inferentia chips. It includes a compiler, runtime, and profiling tools that you can use to optimize the performance of your LLMs.
-
Convert Bit Data Type: Based on the number of parameters from the data, use-case, along with desired inference response speed, adjusting the bit type can optimize memory by increasing or decreasing memory allocation. Resulting in improved performance.
- Loading large models can often have 100s of millions even billions of parameters. To optimize inference performance, you can reduce the standard 32-bit data type per model weight to a 16-bit (you can even go down to 8-bit!) per model weight, increasing throughput of words-per-second and decreasing the memory footprint. With memory reduced, inference speed can increase.
Use Cases:
Decreasing Bit Size = Best for chatbots, or inference requirements requiring fast almost instantaneous responses
Increasing Bit Size = Best for testing stages where inference response times are slower, but throughput is higher
-
Leverage the Neuron Compiler: By using the Neuron Compiler, developers can seamlessly adapt their existing ML models built with popular frameworks like TensorFlow, PyTorch, or MXNet, to a low-level Neuron Executable File Format (NEFF). This becomes the compiled artifact that gets ran on the accelerator to perform efficient and cost-effective inference tasks.
-
Implement Parralell Process Encoding: By processing data simultaneously and dividing the model weights evenly between both Neuron cores, parallel processing can significantly speed up the encoding process. This increased throughput can enable faster model training and inference, which can be critical for real-time machine learning applications.
-
Monitor with CloudWatch: Use AWS CloudWatch to monitor the performance of your LLMs. CloudWatch provides insights on inference throughput and latency, allowing you to fine-tune the performance further.
Benefit from the Efficiency:
Optimizing LLM inference with AWS Inferentia2 can have multiple benefits:
Cost-Optimization: Inferentia2 provides high performance at a low cost, making it a cost-effective solution for running LLMs.
Scalability:: It’s designed to scale, allowing you to handle increasing inference workloads efficiently.
Versatility: Inferentia2 supports all major ML frameworks, making it versatile and easy to integrate into your existing ML workflows.
In conclusion, efficiency plays a pivotal role when dealing with Large Language Models (LLMs). It’s not just about running the models, but harnessing them effectively to generate insightful data. By choosing Inferentia2 and using the recommendtions above, businesses can truly optimize their AI operations reaching new heights in their capabilities.
Thank you!